Mix NLU
自然言語処理のドメインをビルドし、実世界での利用データに基づいて NLU モデルを継続的に改良し、進化させます。 ユーザーインテント(「フライトの予約」)およびエンティティ(「JFK から LAX へ次の水曜日」)を定義し、サンプルの文章を提供することにより、DNN ベースの NLU エンジンをトレーニングします。
NLU のビルド

NLU スタートパックには、通信事業、銀行取引、公益事業といった業界固有のオプションに加え、一般的なソーシャルなインテントやチャットが含まれます。
NLU スターターパック
新規プロジェクトの開始時、インテントやサンプルが事前定義された NLU スターターパック セットから選び、プロジェクトに追加します。
ビジネスインテント(銀行取引、通信事業など)や「ソーシャルな」インテント(挨拶、陳謝、感動、楽しい質問など)に対応しており、簡単に始めることができます。
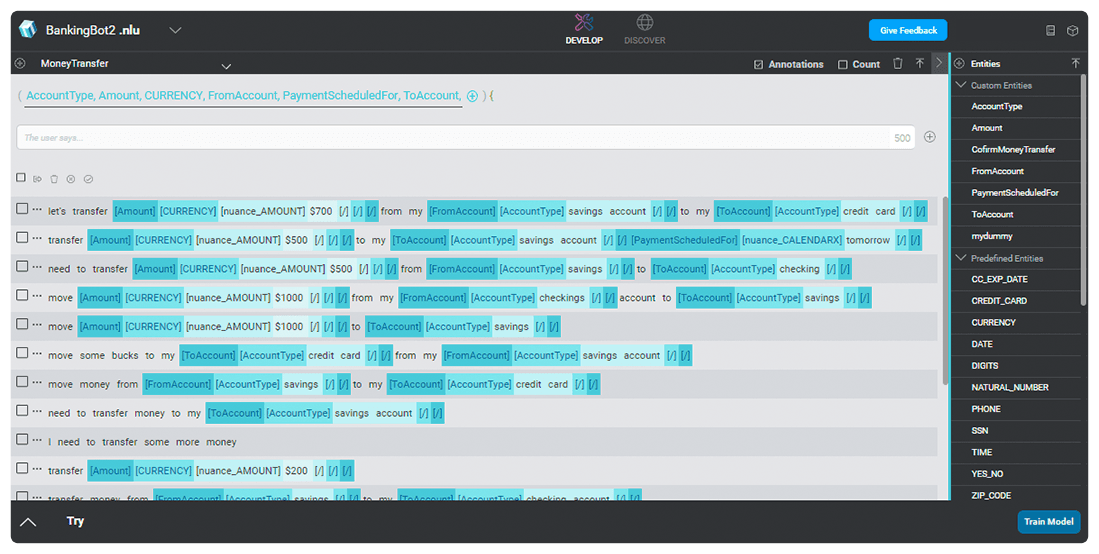
インテントとエンティティの定義
NLU モデルをサンプルフレーズでトレーニングして、何十または何百もの様々なユーザーインテント間で差別化を行えるように学習します。 それぞれのインテントに対して、お客様のリクエストに応えるために必要なエンティティを定義します。 言葉のリストや毎日使う表現に基づいてカスタムエンティティを作成するか、お客様が情報を表現するために利用する様々な方法を理解する数、通貨、日時の既存のエンティティを利用します。
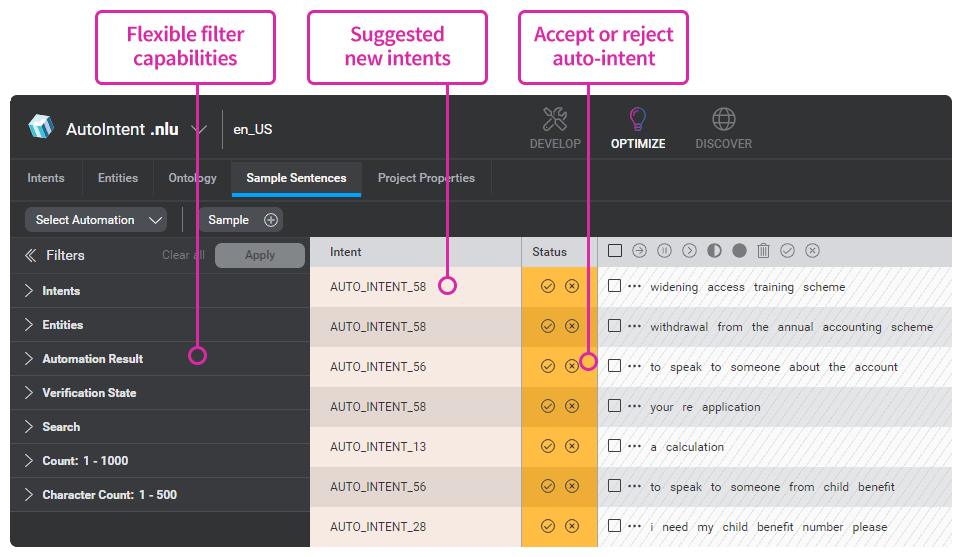
自動インテント検出
Mix.nlu は、インテント別に自動分類する自動インテント機能により、エンドユーザーによるサンプルメッセージ/発話の「タグ付け」プロセスをサポートします。
新しいサンプルを、これに近い既存のインテントに自動的にグループ分けし、既存のインテントの精度を向上させます。
既存のモデルに最も当てはまるものがない場合、新しいインテントが提案され、これもまた自動分類の対象となります。
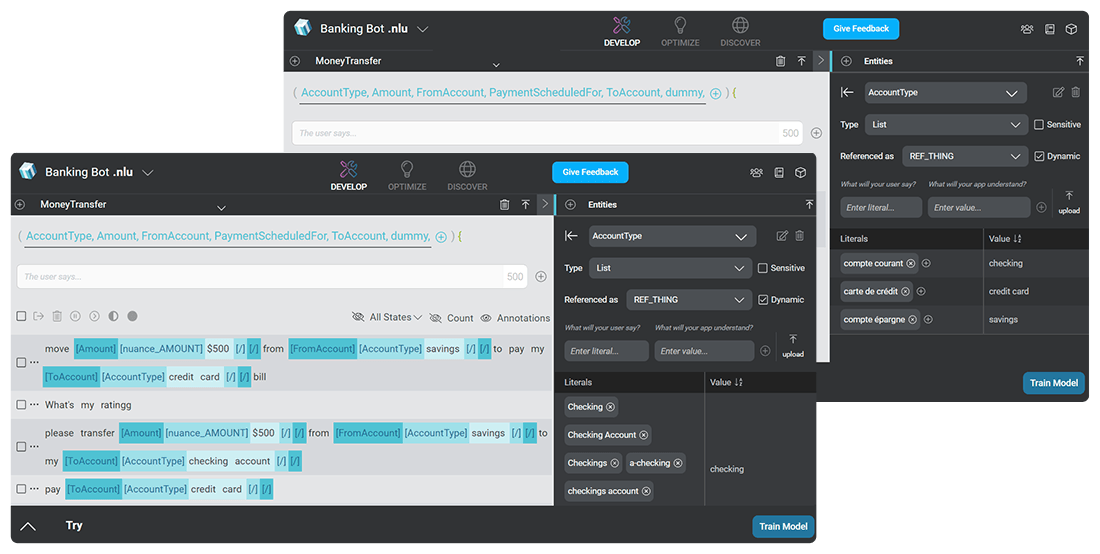
多言語 NLU モデル
Mix では、多言語アプリケーションを単一のプロジェクトで作成および管理できます。 Mix.nlu では、多言語でのインテントとエンティティの単一のセットを作成できます。また、言語固有のトレーニングセットも用意されています。
これにより、より一貫した多言語型ユーザーエクスペリエンスを低コストで提供できます。
テストと調整
NLU フィードバックループ
自然言語理解の最適な結果を得るには、エンドユーザーの会話からのデータを使用して NLU モデルの精度と範囲を継続的に向上させる、AI ベースの自動化されたスケーラブルなフィードバックサイクルが必要です。
Mix.nlu ならこれを実現できます。プロダクションデータへのアクセス、AI ベースの自動インテント検出、手動レビューのサポート、リグレッションテストや本番環境において変更を簡単に測定できる方法を提供します。

NLU と音声認識の調整
トレーニングされた NLU モデルを NLU エンジンに展開し、同時にドメイン言語モデルとして音声文字変換トランスクリプションエンジンにも展開します。 これは音声認識の結果、セマンティック解析、ユーザーの発言の理解において、アプリケーション特有の言語ドメインに基づき、最高の精度を提供します。
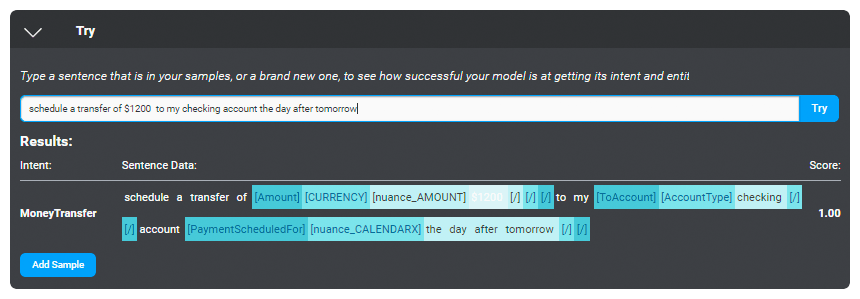
モデルのテスト
任意のタイミングで NLU モデルをトレーニングして、練習の文章に対してテストします。 インテントが密接に重複しすぎているか、自信のレベルを向上させる必要があるか、追加のエンティティが定義される必要のある問題の領域を特定します。
Nuance Mix
Nuance Mix を使用してどのように会話型 AI アプリケーションの設計、開発、テスト、メンテナンスを実現できるかご覧ください。
Nuance Dialog
オムニチャネルの多言語会話型インタラクションを単一のプロジェクト内で簡単に設計できます。
Mix Dashboard
単一のダッシュボードでデザインからビルドまで、そして展開までの Nuance Mix のフル機能にアクセスできます。